
Processing Streaming Data with Apache Spark on Databricks 
This course provides an introduction to using Apache Spark on Databricks to process streaming data. Learners will gain an understanding of Spark abstractions and use the Spark structured streaming APIs to perform transformations on streaming data. ▼
ADVERTISEMENT
Course Feature
![]() Cost:
Cost:
Free Trial
![]() Provider:
Provider:
Pluralsight
![]() Certificate:
Certificate:
Paid Certification
![]() Language:
Language:
English
![]() Start Date:
Start Date:
On-Demand
Course Overview
❗The content presented here is sourced directly from Pluralsight platform. For comprehensive course details, including enrollment information, simply click on the 'Go to class' link on our website.
Updated in [February 21st, 2023]
What does this course tell?
(Please note that the following overview content is from the original platform)
This course will teach you how to use Spark abstractions for streaming data and perform transformations on streaming data using the Spark structured streaming APIs on Azure Databricks.
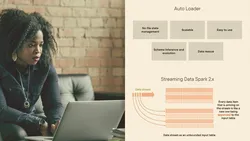
Structured streaming in Apache Spark treats real-time data as a table that is being constantly appended. This leads to a stream processing model that uses the same APIs as a batch processing model - it is up to Spark to incrementalize our batch operations to work on the stream. The burden of stream processing shifts from the user to the system, making it very easy and intuitive to process streaming data with Spark. In this course, Processing Streaming Data with Apache Spark on Databricks, you’ll learn to stream and process data using abstractions provided by Spark structured streaming. First, you’ll understand the difference between batch processing and stream processing and see the different models that can be used to process streaming data. You will also explore the structure and configurations of the Spark structured streaming APIs. Next, you will learn how to read from a streaming source using Auto Loader on Azure Databricks. Auto Loader automates the process of reading streaming data from a file system, and takes care of the file management and tracking of processed files making it very easy to ingest data from external cloud storage sources. You will then perform transformations and aggregations on streaming data and write data out to storage using the append, complete, and update models. Finally, you will learn how to use SQL-like abstractions on input streams. You will connect to an external cloud storage source, an Amazon S3 bucket, and read in your stream using Auto Loader. You will then run SQL queries to process your data. Along the way, you will make your stream processing resilient to failures using checkpointing and you will also implement your stream processing operation as a job on a Databricks Job Cluster. When you’re finished with this course, you’ll have the skills and knowledge of streaming data in Spark needed to process and monitor streams and identify use-cases for transformations on streaming data.
We consider the value of this course from multiple aspects, and finally summarize it for you from three aspects: personal skills, career development, and further study:
(Kindly be aware that our content is optimized by AI tools while also undergoing moderation carefully from our editorial staff.)
What skills and knowledge will you acquire during this course?
This course, Processing Streaming Data with Apache Spark on Databricks, will provide learners with the skills and knowledge to understand the fundamentals of streaming data and how to use Apache Spark to process streaming data. Learners will gain an understanding of the differences between batch processing and stream processing, and the different models that can be used to process streaming data. They will also learn how to read from a streaming source using Auto Loader on Azure Databricks, and how to perform transformations and aggregations on streaming data. Additionally, learners will learn how to use SQL-like abstractions on input streams, and how to make their stream processing resilient to failures using checkpointing. Finally, learners will learn how to implement their stream processing operation as a job on a Databricks Job Cluster. By the end of this course, learners will have acquired the skills and knowledge to process and monitor streams, identify use-cases for transformations on streaming data, and understand the fundamentals of streaming data and how to use Apache Spark to process streaming data.
How does this course contribute to professional growth?
This course contributes to professional growth by providing learners with the skills and knowledge of streaming data in Spark needed to process and monitor streams and identify use-cases for transformations on streaming data. Learners will gain an understanding of the differences between batch processing and stream processing, and the different models that can be used to process streaming data. They will also learn how to read from a streaming source using Auto Loader on Azure Databricks, and how to perform transformations and aggregations on streaming data. Additionally, learners will learn how to use SQL-like abstractions on input streams, and how to make their stream processing resilient to failures using checkpointing. Finally, learners will learn how to implement their stream processing operation as a job on a Databricks Job Cluster. With these skills, learners will be able to apply their knowledge to real-world scenarios and develop their professional growth.
Is this course suitable for preparing further education?
This course is suitable for preparing further education in the field of streaming data and Apache Spark. It covers the fundamentals of streaming data, how to use Apache Spark to process streaming data, and how to use SQL-like abstractions on input streams. Additionally, learners will gain an understanding of the differences between batch processing and stream processing, and the different models that can be used to process streaming data. Furthermore, learners will learn how to make their stream processing resilient to failures using checkpointing and how to implement their stream processing operation as a job on a Databricks Job Cluster. All of these skills and knowledge are essential for further education in the field of streaming data and Apache Spark.
Course Provider

Provider Pluralsight's Stats at AZClass
Pluralsight ranked 16th on the Best Medium Workplaces List.
Pluralsight ranked 20th on the Forbes Cloud 100 list of the top 100 private cloud companies in the world.
Pluralsight Ranked on the Best Workplaces for Women List for the second consecutive year.
AZ Class hope that this free trial Pluralsight course can help your Databricks skills no matter in career or in further education. Even if you are only slightly interested, you can take Processing Streaming Data with Apache Spark on Databricks course with confidence!
31,000 Learners
7,000 Courses
Discussion and Reviews
0.0 (Based on 0 reviews)
Explore Similar Online Courses

NET 6 First Look

Cisco Collaboration Fundamentals: Managing Media Resources ISR Call Control Voicemail and Reporting

Python for Informatics: Exploring Information

Social Network Analysis

Introduction to Systematic Review and Meta-Analysis

The Analytics Edge

DCO042 - Python For Informatics

Causal Diagrams: Draw Your Assumptions Before Your Conclusions

Whole genome sequencing of bacterial genomes - tools and applications
Databricks Fundamentals & Apache Spark Core

Databricks Essentials for Spark Developers (Azure and AWS)

Microsoft Azure Databricks for Data Engineering
 Related Categories
Related Categories
 Popular Providers
Popular Providers
Quiz
 Submitted Sucessfully
Submitted Sucessfully
1. What is the main purpose of this course?
2. What is the difference between batch processing and stream processing?
3. What is the benefit of using Auto Loader on Azure Databricks?
4. What is the goal of using checkpointing?
5. What is the name of the process that automates the process of reading streaming data from a file system?
Correct Answer: Auto Loader

Start your review of Processing Streaming Data with Apache Spark on Databricks